摘要:Innodb的MVCC实现原理学习
什么是MVCC
Multi-Version Concurrency Control(多版本并发控制)是一种并发控制方法,在数据库管理系统中用来提供并发访问数据库的能力,在编程语言中实现事务内存。
MVCC的作用
读不阻塞写,写不阻塞读。提高数据库的并发访问能力!
MVCC只兼容RC和RR两种隔离级别。
数据库多版本读场景
在session1开启一个事务,查询a表的a1记录: root@testdb 01:13:24>set tx_isolation='read-committed'; Query OK, 0 rows affected (0.00 sec) root@testdb 01:13:43>select @@tx_isolation; +----------------+ | @@tx_isolation | +----------------+ | READ-COMMITTED | +----------------+ 1 row in set (0.00 sec) root@testdb 01:13:48>start transaction; Query OK, 0 rows affected (0.00 sec) root@testdb 01:14:16>select * from a where a1=1; +------+------+ | a1 | a2 | +------+------+ | 1 | A1 | +------+------+ 1 row in set (0.00 sec) 在session2上开启一个事务将A1改为A2,但不提交: root@testdb 11:53:18>set tx_isolation='read-committed'; Query OK, 0 rows affected (0.00 sec) root@testdb 01:13:56>select @@tx_isolation; +----------------+ | @@tx_isolation | +----------------+ | READ-COMMITTED | +----------------+ 1 row in set (0.00 sec) root@testdb 01:14:02>start transaction; Query OK, 0 rows affected (0.00 sec) root@testdb 01:14:28>update a set a2='A2' where a1=1; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 在session1上查询结果仍然是A1: root@testdb 01:14:19>select * from a where a1=1; +------+------+ | a1 | a2 | +------+------+ | 1 | A1 | +------+------+ 1 row in set (0.00 sec) 在session2上进行提交: root@testdb 01:14:39>commit; Query OK, 0 rows affected (0.00 sec) 在session1上查询结果变成了A2: root@testdb 01:14:44>select * from a where a1=1; +------+------+ | a1 | a2 | +------+------+ | 1 | A2 | +------+------+ 1 row in set (0.00 sec)
|
可以看到隔离级别是RC的时候,当session2未提交时session1读到的是update前的数据,当session2提交后session1读到的数据是update后的数据。
session1上开启一个事务,查询a表的a1记录: root@testdb 11:51:30>select @@tx_isolation; +-----------------+ | @@tx_isolation | +-----------------+ | REPEATABLE-READ | +-----------------+ 1 row in set (0.00 sec) root@testdb 11:51:54>start transaction; Query OK, 0 rows affected (0.00 sec) root@testdb 11:52:02>select * from a where a1=1; +------+------+ | a1 | a2 | +------+------+ | 1 | A2 | +------+------+ 1 row in set (0.00 sec) session2上开启一个事务,将A2改成A1但不提交: root@testdb 11:52:32>start transaction; Query OK, 0 rows affected (0.00 sec) root@testdb 11:52:50>update a set a2='A1' where a1=1; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 在session1上查到的结果依然为A2: root@testdb 11:52:10>select * from a where a1=1; +------+------+ | a1 | a2 | +------+------+ | 1 | A2 | +------+------+ 1 row in set (0.00 sec) 在session2上进行提交: root@testdb 11:53:04>commit; Query OK, 0 rows affected (0.00 sec) 在session1上查询到的结果依然为A2: root@testdb 11:53:14>select * from a where a1=1; +------+------+ | a1 | a2 | +------+------+ | 1 | A2 | +------+------+ 1 row in set (0.00 sec)
|
可以看出隔离级别是RR的情况下,无论session2是否提交,session1查到的数据都是update前的结果。
MVCC实现原理
从上面可以看出,在不同的隔离级别下,session1看到的数据是不同的。这由innodb中的MVCC通过undo实现的!
事务的隔离性是由锁来实现,而原子性、一致性、持久性通过redo和undo完成。
什么是redo
redo log用来保证事务的原子性和持久性;redo恢复提交事务修改的页操作;redo是物理日志,记录的是页的物理修改操作;redo存放在redo log文件中;
什么是undo
undo log用来保证事务的一致性;undo回滚行记录到某个特定版本;undo是逻辑日志,根据每行记录进行记录;undo存放在共享表空间的undo段中;
rollback segment
在innodb中,undo log被划分成多个段,具体某行的undo log就保存在某个段中,称为回滚段。
Innodb中MVCC的实现过程
1、旧数据存储在UNDO中,再通过DB_ROLL_PTR回溯查找历史版本
先看下InnoDB的行存储格式(默认是compact格式):

可以看到每行数据有个DB_ROLL_PTR(7字节的回滚指针),用于指向该行修改前的上一个历史版本(InnoDB里,会将row data修改前的旧数据存储在UNDO中)。当插入的是一条新数据时,记录上对应的回滚段指针为NULL!如下图:
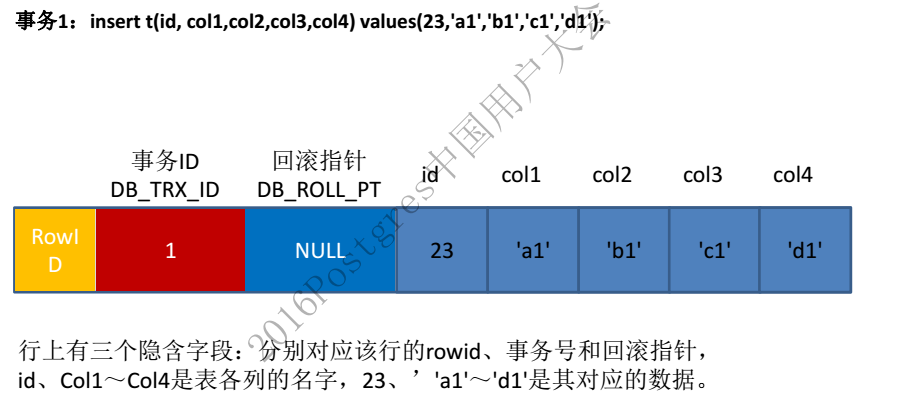
更新记录时,原记录将被放入到undo表空间中,并通过DB_ROLL_PTR指向该记录。session1查询返回的未修改数据就是从这个UNDO中返回的。MySQL就是根据记录上的回滚段指针及事务ID判断记录是否可见,如果不可见继续按照DB_ROLL_PTR继续回溯查找。如下图:

2、通过read view判断行记录是否可见
RR隔离级别下:在每个事务开始的时候,会将当前系统中的所有的活跃事务拷贝到一个列表中(read view)。
RC隔离级别下:在事务中的每个语句开始时,会将当前系统中的所有的活跃事务拷贝到一个列表中(read view) 。
然后按照以下逻辑判断事务的可见性:
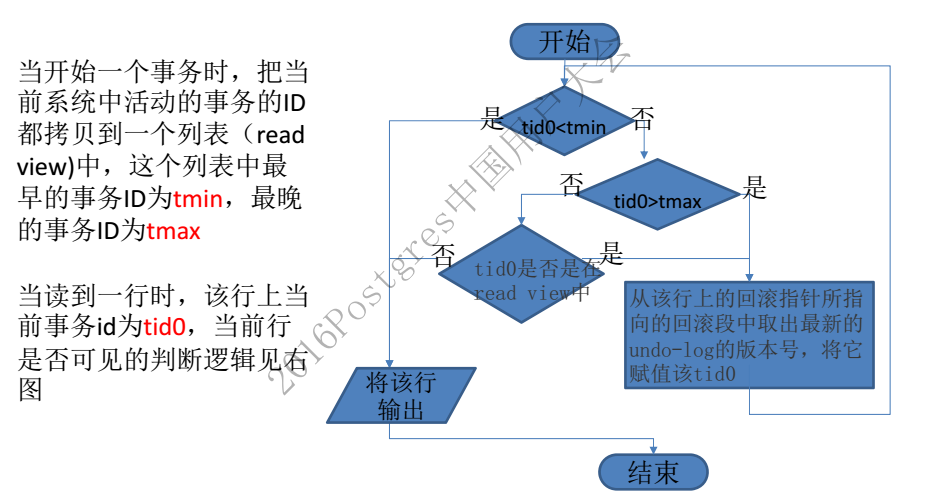
并不是用当前事务ID与表中各个数据行上的事务ID去比较的,而是在每个事务开始的时候,会将当前系统中所有的活跃事务拷贝到read view列表,根据read view最早一个事务ID和最晚的一个事务ID做比较,这样就能确保在当前事务之前没提交的所有事务的变更及后续新启动的事务的变更在当前事务中都是看不到的。当前事务自身的变更是可以看到的。
资料来源:老叶茶馆微信公共号
